
Web crawler
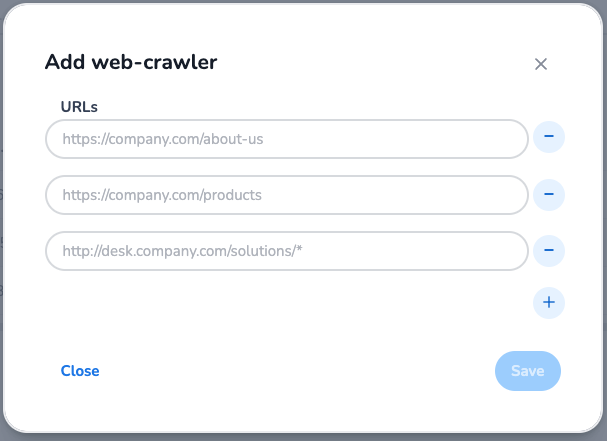
Adding URLs
Web crawlers can extract information from specified website URLs. Enter multiple URLs for comprehensive data gathering.
In order for the configured URLS to be updated in real-time (daily) you als need to enable the scheduled synchronization in the knowledge settings.
URL Formatting
Add an asterisk (*) after a trailing slash in URLs to enable the crawler to traverse all subsequent URLs in that directory path. Example: http://desk.company.com/solutions/*.
Be careful with using the asterisk (*). Using this feature can result in a large amount of pages to be scraped. This can result in long synchronization times and also degraded quality of the knowledge search functionality within HALO. Be considerate of which pages are of actually value to your knowledge base.
Note that web crawlers cannot process parameterized URLs with a question mark (?) and key-value pairs separated by an ampersand (&). The below table shows readable URLs on the left side and those that can't be read on the right.
✅ |
|
|---|---|
https://www.cm.com/about | https://www.cm.com/products/?category=communication |
https://www.cm.com/contact | https://www.cm.com/blog/?tag=technology |
https://www.cm.com/careers | https://www.cm.com/careers/?location=remote&role=developer |
https://www.cm.com/products | https://www.cm.com/events/?month=november&year=2023 |
https://www.cm.com/blog | https://www.cm.com/support/?topic=billing&priority=high |
About the web crawling
Whitelisting user-agent: If the web-crawler does not return any results for your website it might be the case case that our crawler is being blocked by your website. In order to allow our crawler to acces your site you can whitelist the following user-agent:
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.5993.70 Safari/537.36 (compatible; CMbot/1.0; +http://www.cm.com; web scraping for knowledge; contact: support@cm.com)
Crawler Duration: The crawler can operate for up to 48 hours continuously. Especially when asterisks are being used synchronizations can take up to a few hours to complete.
Source Quality: The best source for high-quality answers is naturally written text. Product descriptions such as "Color: Black" are not effective.
Web-crawler Blacklist: You can also exclude certain web pages from being crawled using the Web Crawler Blacklist on the Profile Settings screen. More about this topic here.