As part of our commitment to transparency and continuous improvement, we share the theoretical underpinnings of HALO’s AI framework. Understanding the mechanics of HALO’s Agentic Retrieval Augmented Generation (Agentic RAG) algorithm can help you better appreciate how it enhances and refines interactions within your organization. This powerful system ensures that communication is not only accurate but also contextually relevant, harnessing the latest advancements in Agentic AI.
The Role of LLMs and Agentic RAG in HALO
HALO leverages the capabilities of Large Language Models (LLMs) while mitigating common pitfalls such as inaccuracies and inappropriate outputs. This is achieved through an Agentic RAG framework. Unlike classical RAG—which typically performs a single retrieval pass—Agentic RAG combines retrieval with strategic, multi-step search and generation to optimize performance.
In practical terms, HALO retrieves and iteratively refines the evidence it needs before calling an LLM. By supplying rich, relevant source content to the LLM, HALO delivers more accurate and contextually appropriate responses.
Requirements
To effectively use HALO and take full advantage of its Agentic RAG capabilities, certain prerequisites must be met:
-
Knowledge: Provide comprehensive knowledge by adding and synchronizing resources. This information is processed into smaller text segments (“chunks”) and stored in an internal database. Well-structured, up-to-date content is crucial for optimal retrieval—especially as Agentic RAG runs multiple targeted searches.
-
Style: Configure the desired agent behavior, including language preferences and tone of voice. This ensures responses align with your organization’s communication standards.
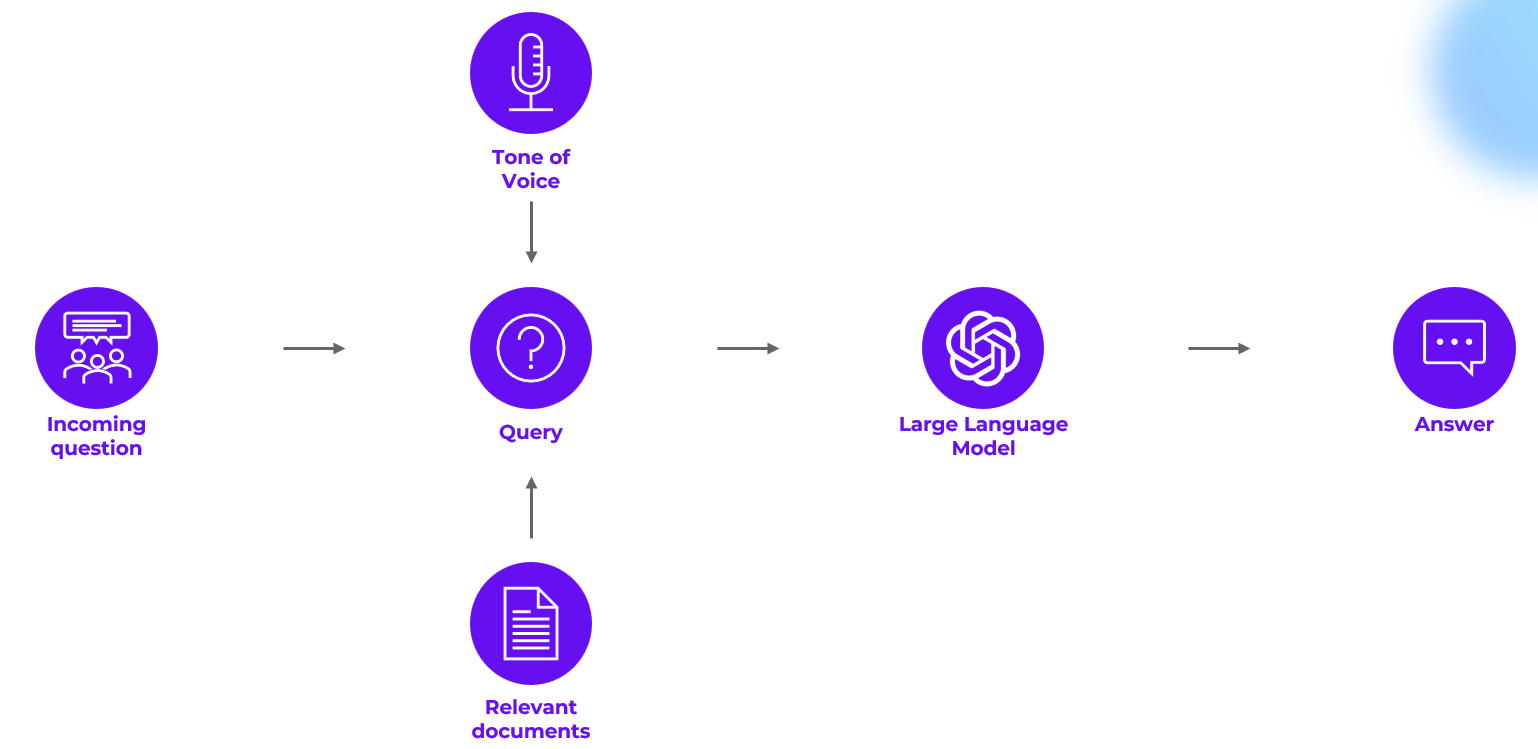
Approach
When a user submits a query, HALO employs Agentic RAG through the following steps:
-
Planning and query understanding: HALO interprets the request, detects multi-part questions, and drafts an initial search plan.
-
Evidence gathering (agentic retrieval): HALO executes multiple parallel and/or iterative searches across your pre-chunked knowledge base. It uses early results to inform follow-up queries, dynamically adjusts its strategy, and determines when it has sufficient, high-quality evidence. The most relevant chunks are then used.
-
Synthesis: The LLM composes a response that adheres to your configured tone of voice and relies solely on the retrieved context. If gaps remain, HALO can trigger an additional retrieval pass before finalizing the answer.
By integrating these agentic processes, HALO’s RAG framework upholds the integrity and accuracy of AI-driven interactions, fostering trust and reliability in your digital communications ecosystem.
Learning Snippet
Learn more about the RAG algorithm's functionality within HALO by watching our engaging Learning Snippet.