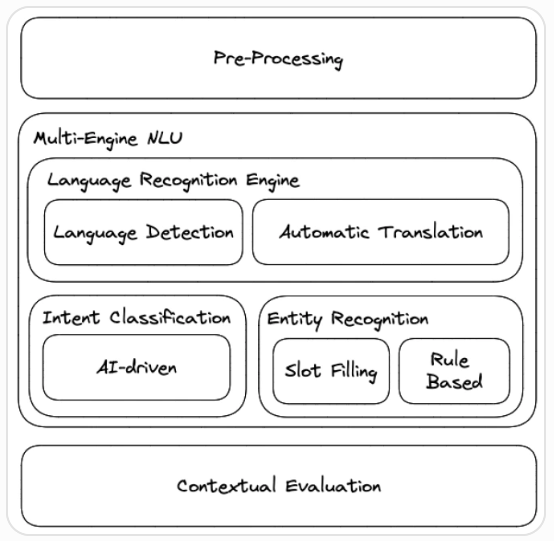
Natural Language Processing
To process and understand incoming end-user questions, Conversational AI Cloud uses a Natural Language Processing (NLP) pipeline consisting of several steps. This article explains the different parts that make up Conversational AI Cloud’s NLP.
Language Support
|
region |
language |
m of speakers |
simple matching |
basic NLP |
full NLP |
culture |
|
Western Europe/World |
English |
360 |
✓ |
✓ |
✓ |
en |
|
Western Europe |
Dutch |
21 |
✓ |
✓ |
✓ |
nl |
|
Western Europe |
French |
75 |
✓ |
✓ |
✓ |
fr |
|
Western Europe |
German |
89 |
✓ |
✓ |
✓ |
de |
|
Western Europe |
Italian |
59 |
✓ |
✓ |
✓ |
it |
|
Western Europe/Latin America |
Spanish |
405 |
✓ |
✓ |
✓ |
es |
|
Eastern Europe |
Polish |
40 |
✓ |
✓ |
|
pl |
|
Eastern Europe |
Ukrainian |
30 |
✓ |
✓ |
|
uk |
|
Eastern Europe |
Romanian |
24 |
✓ |
✓ |
|
ro |
|
Eastern Europe |
Hungarian |
13 |
✓ |
✓ |
|
hu |
|
Eastern Europe |
Slovak |
12 |
✓ |
✓ |
|
sl |
|
Eastern Europe |
Czech |
10 |
✓ |
✓ |
|
cs |
|
Northern Europe |
Swedish |
9 |
✓ |
✓ |
✓ |
sv |
|
Northern Europe |
Danish |
6 |
✓ |
✓ |
✓ |
da |
|
Northern Europe |
Norwegian |
5 |
✓ |
✓ |
✓ |
no |
|
Northern Europe |
Finnish |
5 |
✓ |
✓ |
|
fi |
|
Southern Europe |
Greek |
12 |
✓ |
✓ |
|
el |
|
Southern Europe/Latin America |
Portuguese |
215 |
✓ |
✓ |
✓ |
pt |
|
Southern Europe |
Serbo-Croatian |
19 |
✓ |
✓ |
|
sr,hr |
|
East Asia |
Simplified Chinese |
1052 |
✓ |
✓ |
✓ |
zh-CN |
|
East Asia |
Traditional Chinese |
45 |
✓ |
✓ |
✓ |
zh-HK |
|
Middle East/World |
Arabic |
280 |
✓ |
✓ |
|
ar |
|
Middle East |
Turkish |
63 |
✓ |
✓ |
|
tr |
Basic NLP includes stemming & lemmatization – this is needed for basic production.
Full NLP includes language-specific rules for cleanups, overrides, and rephrase.
Note: Languages that are not on this list, can currently only be used in FAQ projects, so without an open search for users. This is because in an FAQ project, no natural language processing is needed. The Questions are predefined, so recognition is strictly based on a keyword search.